
with N8N and AI Agents to health check VM — Here’s How I Did It
Hey folks, If you’re running Kubernetes, Docker, or even just a VM, you know how important it is to keep an eye on things before problems blow up.
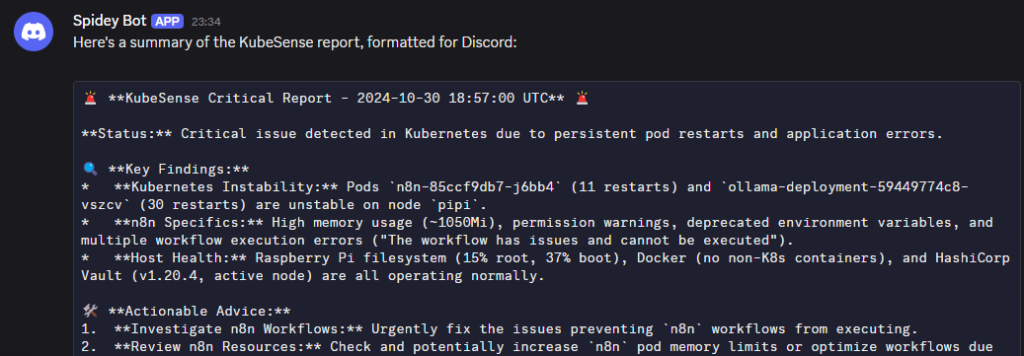
I recently built a pretty slick workflow using n8n that automatically checks my Kubernetes pods, Docker containers, and the VM itself. The best part? It uses AI to analyze the status and send me alerts on email and Discord, so I don’t have to babysit my cluster 24/7.
Why bother automating this stuff?
Because no one has time to manually check logs or pod statuses every hour. Plus, automation means less chance of missing something important and more time to focus on building cool stuff.
How my n8n workflow works
Here’s the gist:
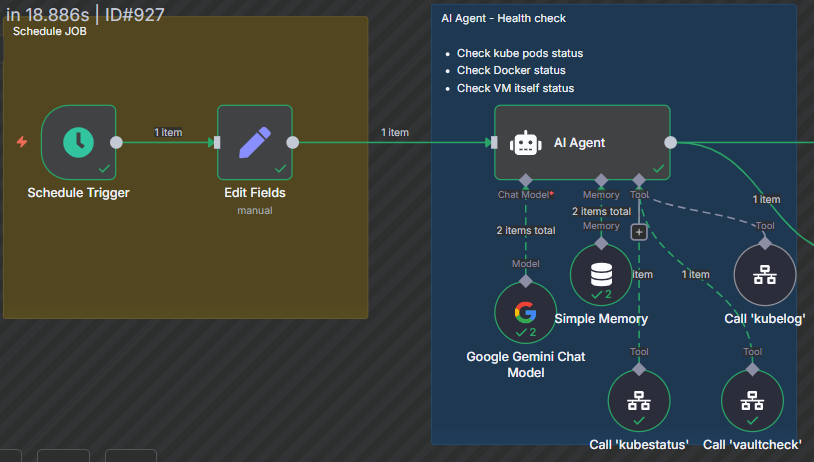
- Scheduled trigger kicks off the whole thing at set intervals (you decide how often).
- AI Agent does the heavy lifting — it checks pod statuses, Docker container health, and VM resources.
- It calls some custom tools I set up inside n8n to get pod logs and statuses.
- Then I uses Google Gemini chat AI (because, why not?) with some memory to keep context.
- The AI output gets polished by an OpenAI model and finally…
- Alerts get sent out via email and Discord.
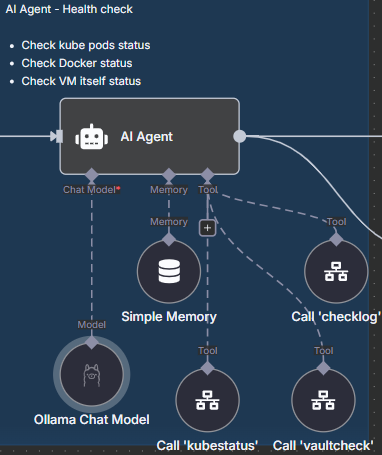
PS:You could also you use your local AI-model. Select Ollama model, you could select the AI Model which fit the best job.
What I like about this setup
- It finds issues early — catching pods that are crashing or restarting too much.
- Smart analysis — the AI doesn’t just spit logs, it gives me actionable insights.
- Multi-channel alerts — so I see problems no matter if I’m on email or Discord.
Troubleshooting tips if you try this
- Make sure your AI Agent is linked properly to the right tools — if the
kubelogtool isn’t running, check connections and inputs. - Verify n8n has permission to run
kubectlcommands. - Double-check pod and container names you pass into the workflow.
Sometime, The Tools will not be trigger by the agent. It will be depends on how is your system message.
What’s next on my list?
- Get detailed pod logs automatically when something’s wrong.
- Add Vault security checks (I’m using HashiCorp Vault in my setup).
- Connect to Slack and other notification channels.
- Improve AI memory for longer-term trend analysis.
This workflow saved me a ton of manual work and gave me peace of mind that my cluster is being watched over, even when I’m not.
If you want the n8n workflow file or need help tweaking it, drop me a message!